
LLM과 LLaMA
LLM은 Large Language Model의 약자로, 거대언어모델이라는 뜻이다. 방대한 양의 데이터를 기반으로 사전학습된 초대형 딥러닝 알고리즘이다.
LLaMA(Large Language Model Meta AI) 는 Meta가 공개한 대규모 인공지능 언어모델이다. 텍스트생성, 대화 등 다양하고 복잡한 작업을 수행할 수 있는 인공지능이다.
Understanding the Transformer Architecture of LLaMA:
바닐라 트랜스포머와 LLaMA의 다이어그램

Pre-normalization Using RMSNorm:
LLaMA 접근 방식에서는 변환기 하위계층의 입력을 정규화 하기 위해 RMSNorm이라는 기술이 사용된다.
layer 정규화와 관련된 계산 비용을 최적화 하도록 설계된다.
RMSNorm은 LayerNorm과 유사한 성능을 제공하지만 실행 시간을 크게 줄인다.

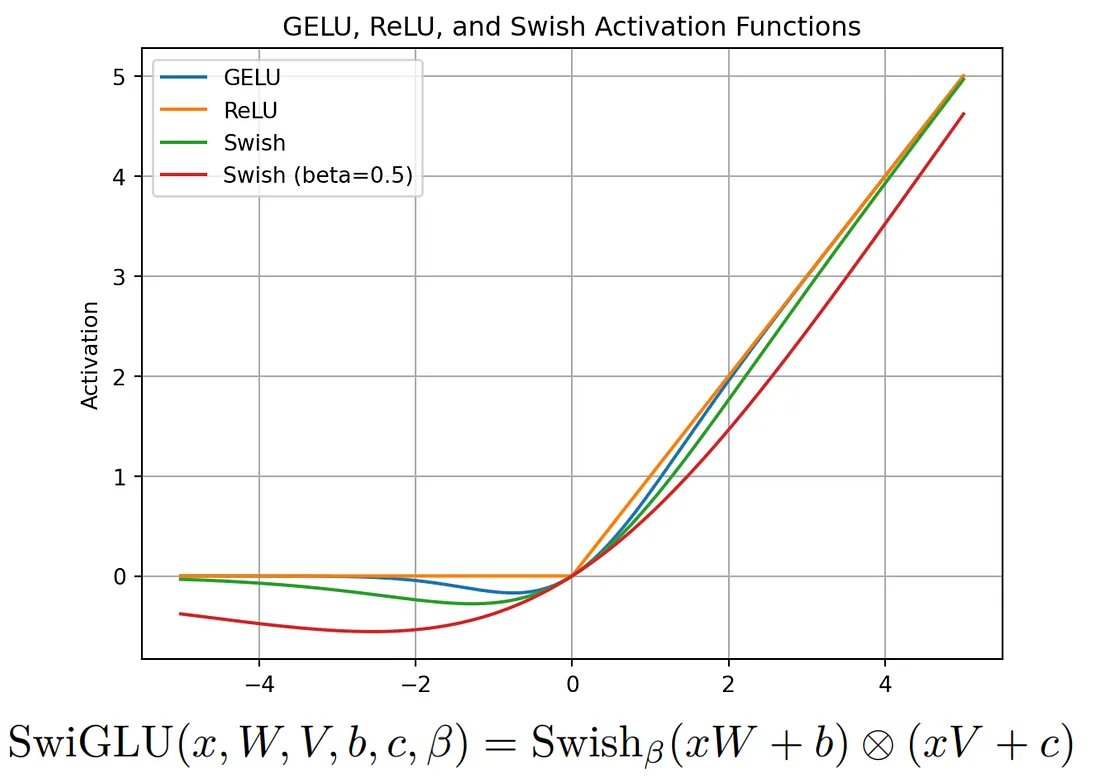
SwiGLU Activation Function:
LLaMA는 PaLM에서 영감을 받아 SwiGLU 활성화 기능을 도입했다. SwiGLU를 이해하려면 먼저 Swish 활성화 기능을 이해하는 것이 중요하다. SwiGLU는 Swish를 확장하고 입력 활성화를 분할하고 곱하기 위해 조밀한 네트워크가 있는 사용자 정의 레이어를 포함한다. 보다 정교한 활성화 기능을 도입해 모델의 표현력을 높이는 것이 목표이다.
Rotary Embeddings (RoPE):
RoPE는 LLaMA에서 사용되는 위치 임베딩 유형이다. 이는 회전행렬을 사용하여 절대 위치 정보를 인코딩하며 자연스럽게 self-attention 공식에 명시적인 상대 위치 종속성을 포함한다.
Pre-trained dataset
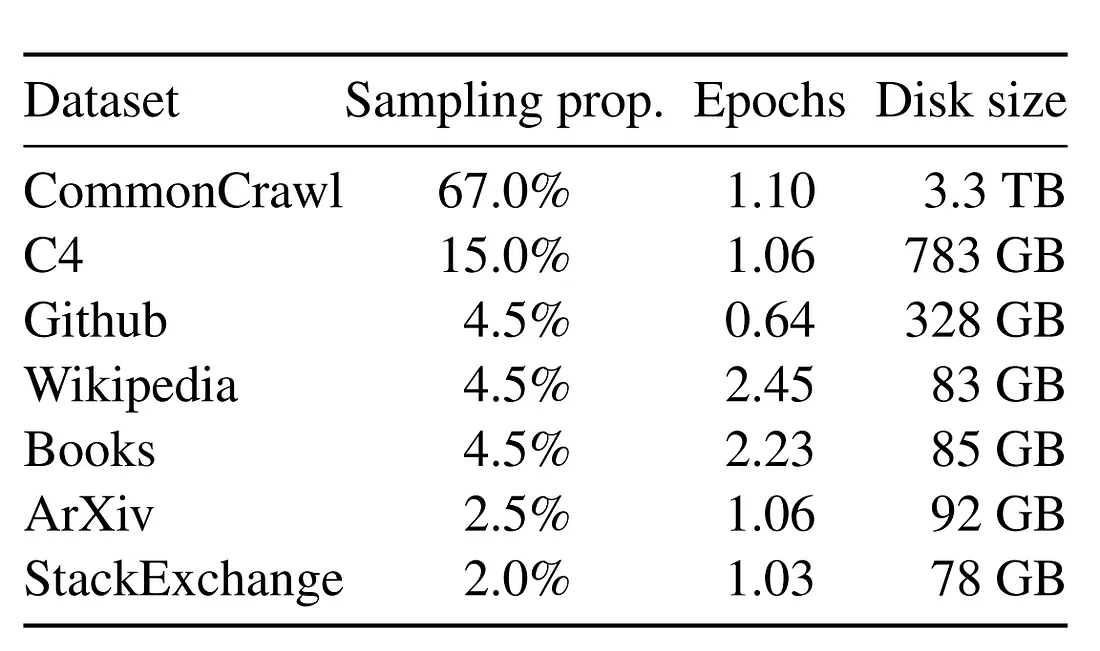
LLaMA의 데이터셋 구성을 보면 위키백과의 인용출처로 쓰일 수 있는가를 판별하는 분류기를 학습시켜서 이를 통과한 페이지만 학습에 투입시켰다.
github, widipedia 등이 학습에 투입됐다.
Meta AI는 LLaMA 학습을 위해 다른 LLMs의 학습 데이터 소스를 재사용하였다. (총 4.75 TB) Wikipedia의 경우, 2022년 6월~8월까지의 20개국(bg, ca, cs, da, de, en, es, fr, hr, hu, it, nl, pl, pt, ro, ru, sl, sr, sv, uk) 데이터로 아쉽게도 한국어는 빠져있다. 사용 인구가 많은 동아시아 문자(kr, cn, jp)가 빠진 이유는 2Bytes 문자라서 빠진 것이 아닐까 추측된다.
Train
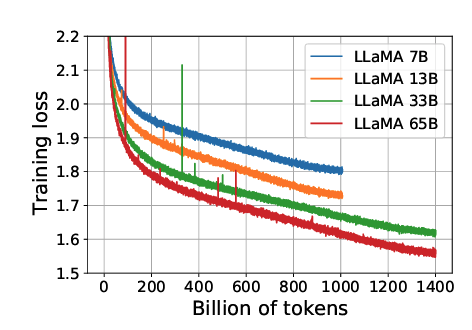
아래는 모델 크기에 따른 파라미터를 보여주는데, 33B, 65B도 꽤 높은 러닝 레이트로 학습시켰음을 알 수 있다.
clip grad를 1.0으로 두고 학습했는데 별로 튀지 않고 로스가 잘 떨어진다.

학습 시간은 65B 학습을 A100 80G 2048장 그러니까, 256노드로 진행해서 1.4T 토큰 학습에 21일 걸렸다고 한다. 380 tokens/sec/GPU on 2048 A100 GPU(80GB) → 256 대 GPU Servers 사용
Result
아래는 라마 모델의 평가 결과이다. 이 결과를 보면 같은 모델 크기에서 라마가 경쟁력이 있고, 작은 모델도 잘 된다는 것을 볼 수 있다.
라마 13B가 GPT3보다 수치가 앞서고 GPT3의 높은 성능을 생각해 보면 이런 수치가 모델의 성능을 완전히 드러내기에는 부족한 감이 있다.
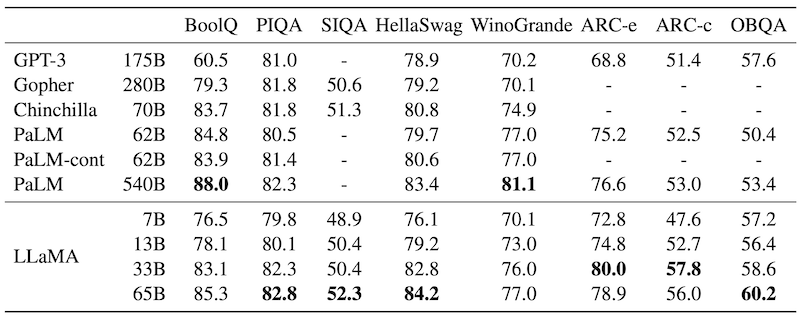
- LLaMA-65B는 NaturalQuestions와 TriviaQA에서 SOTA 성능을 보임
- LLaMA-13B는 Chinchilla와 경쟁할 수 있는 수준이며 GPT-3과 비교하였을 때 전 벤치마크에서 압도적인 성능을 보임
- LLaMA-13B는 V100에서도 추론할 수 있는 모델 사이즈임
LLaMA-13B의 경우 GPT-3보다 10배이상 작음에도 불구하고 대부분의 평가서 GPT-3보다 우수한 성능을 보이며, 더 나아가 LLaMA-65B의 경우 대부분의 벤치마크에서 Chinchilla, Gopher, GPT-3, PaLM와 유사하거나 더 뛰어난 결과를 보였다. LLaMA는 향후 더 큰 모델에 더 많은 token을 학습시킨 모델을 발표할 계획이다.
현재 GPT-3(175B)기반 ChatGPT가 A100 GPU 8대(서버 1대)로 서비스되고 있다라고 추정되고 있다.
반면 LLaMA-13B은 V100 (32GB) 1대로 실행시킬 수 있으므로 ChatGPT에 비해 추론 비용을 크게 줄일 수 있을 것으로 예상된다.
GitHub: https://github.com/bvnohz/Artificial_Intelligence
GitHub - bvnohz/Artificial_Intelligence
Contribute to bvnohz/Artificial_Intelligence development by creating an account on GitHub.
github.com
Paper : https://arxiv.org/abs/2302.13971
LLaMA: Open and Efficient Foundation Language Models
We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and show that it is possible to train state-of-the-art models using publicly available datasets exclusively, witho
arxiv.org
'Prompt Engineering' 카테고리의 다른 글
| LangChain RAG (0) | 2024.01.14 |
|---|---|
| 자연어 처리 (NLP: Natural Language Processing) (31) | 2024.01.09 |
| Prompt Engineering (1) | 2023.12.28 |